DUMP is the project name of a distributed social network platform, that not only connects the profiles of its users but also offers services on top of this social network. The aim of the project is to create a concept that is possible to be implemented in software and should result in the migration of centralised services as we know them on the public internet towards instances on the DUMP.
Last update: 2017-03-07
This project is on halt, have a look at LifeSocial.
We have two nodes that each have two registered users with profiles (name, email address, avatar etc.). Both nodes X and Y have the module for a marketplace service. User Adam can use this module on his node and create a market listing for a pair of socks that he wants to sell. This listing on the market is published with his profile which he created on the node and saved in a database that is used by the module. User Beatrice who is a user on the same node can now see the listing on the node as well, by requesting a page that is supplied by the module inside the nodes user interface.
If we extend this functionality over the network, the module on Adams and Beatrices node then distributes the listing to all known other nodes that have enabled the market place module. So the users on node Y can also see the listing via the module.Let's begin with the most basic layer that will serve us as the fundation: a distributed social network.
In this distributed network common protocols and software packages are implemented and can be freely used by anyone with a computer. If I choose to participate in this network with my own hardware resources, I install the software for a node and run it on my own device. Since I want to be able to communicate with other nodes, it has implemented protocols that allow the exchange of messages.
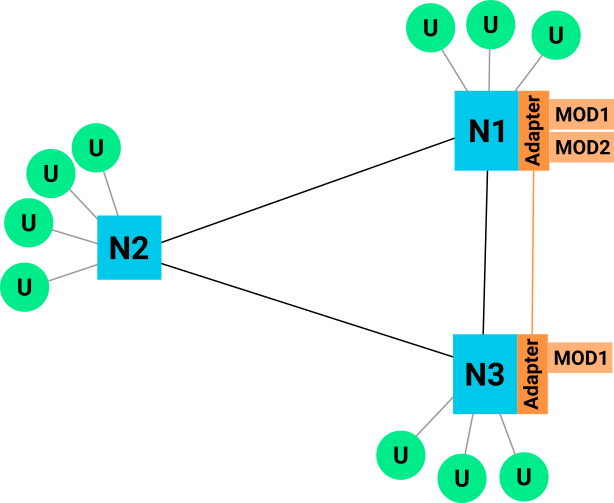
The adapter is a software component that needs to be implemented for at least one social network out there. The resulting adapter-API should be as accessable as possible to ensure adoption. The heavy lifting is then done by the adapter itself, which is a project agnostic part of the stack.
I'm not yet sure how much functionality the adapter should contain. Maybe the better approach would be to define a class of core modules that are replaceable. E.g. core modules for
Every module that provides a functionality like a market or services exchange needs a storage backend. This storage backend must be in a format that is easily usable (e.g. a common SQL DBMS connection) or even embedded in the node software stack. Having its own backend provides the best compatibility but also needs more configuration by the nodes administrator. Embedding it would mean the adapter handles all file operations between the modules and the node stack.
Every module instance should be able to share its data with other instances of the same type. This way a distributed service network caches and publishes all usable data at every node in the network. This means there must be a seperation between user profile data and the module specific data. A connection between those two parts would need to be authorised by the owner of the data.
Example. User Steve creates a selling offer for his car in a market module. His offer is a data object that belongs to the module and will be distributed over the network. If user Stephanie, who belongs to another node, sees the offer from Steve, she would not see any user related information about Steve as long as she does not request authorisation to view his profile, which Steve must accept.
To extend the functionality, an implemented adapter can be used by modules. Questions that arise in relation to the API between adapter and module:
To go even further one could implement the distribution of modules via the service network. This would enable automatically extending the service network onto nodes that do not yet have a module (or a specific version of a module). This could also offer an update mechanism for modules of the same type, varying in version.
Problems arise in the trust of automatically pulled/installed modules. They also need to handle version compatibility if newer versions overwrite older ones and overtake the storage. What if module versions on different nodes are incompatible? Should the newer version force an update?
My name is Dominik Pataky and this is Jackass my small thesis in computer science at TU Dresden.
You can contact me via email dominik.pataky@tu-dresden.de, GPG 0x80BF7C9C5B62468F.